Phần Khái niệm giúp bạn tìm hiểu về các bộ phận của hệ thống Kubernetes và các khái niệm mà Kubernetes sử dụng để biểu diễn cụm cluster của bạn, đồng thời giúp bạn hiểu sâu hơn về cách thức hoạt động của Kubernetes.
This is the multi-page printable view of this section. Click here to print.
Các khái niệm
- 1: Tổng quan
- 1.1: Kubernetes là gì
- 2: Kiến Trúc Cluster
- 2.1: Leases
- 2.2: Các khái niệm nền tảng của Cloud Controller Manager
- 2.3: Kubernetes - Khả năng tự phục hồi (Self-Healing)
- 2.4: Proxy Đa Phiên Bản (Mixed Version Proxy)
- 3: Containers
1 - Tổng quan
1.1 - Kubernetes là gì
Trang tổng quan của Kubernetes.
Kubernetes là một nền tảng nguồn mở, khả chuyển, có thể mở rộng để quản lý các ứng dụng được đóng gói và các service, giúp thuận lợi trong việc cấu hình và tự động hoá việc triển khai ứng dụng. Kubernetes là một hệ sinh thái lớn và phát triển nhanh chóng. Các dịch vụ, sự hỗ trợ và công cụ có sẵn rộng rãi.
Tên gọi Kubernetes có nguồn gốc từ tiếng Hy Lạp, có ý nghĩa là người lái tàu hoặc hoa tiêu. Google mở mã nguồn Kubernetes từ năm 2014. Kubernetes xây dựng dựa trên một thập kỷ rưỡi kinh nghiệm mà Google có được với việc vận hành một khối lượng lớn workload trong thực tế, kết hợp với các ý tưởng và thực tiễn tốt nhất từ cộng đồng.
Quay ngược thời gian
Chúng ta hãy xem tại sao Kubernetes rất hữu ích bằng cách quay ngược thời gian.

Thời đại triển khai theo cách truyền thống: Ban đầu, các ứng dụng được chạy trên các máy chủ vật lý. Không có cách nào để xác định ranh giới tài nguyên cho các ứng dụng trong máy chủ vật lý và điều này gây ra sự cố phân bổ tài nguyên. Ví dụ, nếu nhiều ứng dụng cùng chạy trên một máy chủ vật lý, có thể có những trường hợp một ứng dụng sẽ chiếm phần lớn tài nguyên hơn và kết quả là các ứng dụng khác sẽ hoạt động kém đi. Một giải pháp cho điều này sẽ là chạy từng ứng dụng trên một máy chủ vật lý khác nhau. Nhưng giải pháp này không tối ưu vì tài nguyên không được sử dụng đúng mức và rất tốn kém cho các tổ chức để có thể duy trì nhiều máy chủ vật lý như vậy.
Thời đại triển khai ảo hóa: Như một giải pháp, ảo hóa đã được giới thiệu. Nó cho phép bạn chạy nhiều Máy ảo (VM) trên CPU của một máy chủ vật lý. Ảo hóa cho phép các ứng dụng được cô lập giữa các VM và cung cấp mức độ bảo mật vì thông tin của một ứng dụng không thể được truy cập tự do bởi một ứng dụng khác.
Ảo hóa cho phép sử dụng tốt hơn các tài nguyên trong một máy chủ vật lý và cho phép khả năng mở rộng tốt hơn vì một ứng dụng có thể được thêm hoặc cập nhật dễ dàng, giảm chi phí phần cứng và hơn thế nữa. Với ảo hóa, bạn có thể có một tập hợp các tài nguyên vật lý dưới dạng một cụm các máy ảo sẵn dùng.
Mỗi VM là một máy tính chạy tất cả các thành phần, bao gồm cả hệ điều hành riêng của nó, bên trên phần cứng được ảo hóa.
Thời đại triển khai Container: Các container tương tự như VM, nhưng chúng có tính cô lập để chia sẻ Hệ điều hành (HĐH) giữa các ứng dụng. Do đó, container được coi là nhẹ (lightweight). Tương tự như VM, một container có hệ thống tệp (filesystem), CPU, bộ nhớ, process space, v.v. Khi chúng được tách rời khỏi cơ sở hạ tầng bên dưới, chúng có thể khả chuyển (portable) trên cloud hoặc các bản phân phối Hệ điều hành.
Các container đã trở nên phổ biến vì chúng có thêm nhiều lợi ích, chẳng hạn như:
- Tạo mới và triển khai ứng dụng Agile: gia tăng tính dễ dàng và hiệu quả của việc tạo các container image so với việc sử dụng VM image.
- Phát triển, tích hợp và triển khai liên tục: cung cấp khả năng build và triển khai container image thường xuyên và đáng tin cậy với việc rollbacks dễ dàng, nhanh chóng.
- Phân biệt giữa Dev và Ops: tạo các images của các application container tại thời điểm build/release thay vì thời gian triển khai, do đó phân tách các ứng dụng khỏi hạ tầng.
- Khả năng quan sát không chỉ hiển thị thông tin và các metric ở mức Hệ điều hành, mà còn cả application health và các tín hiệu khác.
- Tính nhất quán về môi trường trong suốt quá trình phát triển, testing và trong production: Chạy tương tự trên laptop như trên cloud.
- Tính khả chuyển trên cloud và các bản phân phối HĐH: Chạy trên Ubuntu, RHEL, CoreOS, on-premises, Google Kubernetes Engine và bất kì nơi nào khác.
- Quản lý tập trung ứng dụng: Tăng mức độ trừu tượng từ việc chạy một Hệ điều hành trên phần cứng ảo hóa sang chạy một ứng dụng trên một HĐH bằng logical resources.
- Các micro-services phân tán, elastic: ứng dụng được phân tách thành các phần nhỏ hơn, độc lập và thể được triển khai và quản lý một cách linh hoạt - chứ không phải một app nguyên khối (monolithic).
- Cô lập các tài nguyên: dự đoán hiệu năng ứng dụng
- Sử dụng tài nguyên: hiệu quả
Tại sao bạn cần Kubernetes và nó có thể làm những gì?
Các container là một cách tốt để đóng gói và chạy các ứng dụng của bạn. Trong môi trường production, bạn cần quản lý các container chạy các ứng dụng và đảm bảo rằng không có khoảng thời gian downtime. Ví dụ, nếu một container bị tắt đi, một container khác cần phải khởi động lên. Điều này sẽ dễ dàng hơn nếu được xử lý bởi một hệ thống.
Đó là cách Kubernetes đến với chúng ta. Kubernetes cung cấp cho bạn một framework để chạy các hệ phân tán một cách mạnh mẽ. Nó đảm nhiệm việc nhân rộng và chuyển đổi dự phòng cho ứng dụng của bạn, cung cấp các mẫu deployment và hơn thế nữa. Ví dụ, Kubernetes có thể dễ dàng quản lý một triển khai canary cho hệ thống của bạn.
Kubernetes cung cấp cho bạn:
- Service discovery và cân bằng tải
Kubernetes có thể expose một container sử dụng DNS hoặc địa chỉ IP của riêng nó. Nếu lượng traffic truy cập đến một container cao, Kubernetes có thể cân bằng tải và phân phối lưu lượng mạng (network traffic) để việc triển khai được ổn định. - Điều phối bộ nhớ
Kubernetes cho phép bạn tự động mount một hệ thống lưu trữ mà bạn chọn, như local storages, public cloud providers, v.v. - Tự động rollouts và rollbacks
Bạn có thể mô tả trạng thái mong muốn cho các container được triển khai dùng Kubernetes và nó có thể thay đổi trạng thái thực tế sang trạng thái mong muốn với tần suất được kiểm soát. Ví dụ, bạn có thể tự động hoá Kubernetes để tạo mới các container cho việc triển khai của bạn, xoá các container hiện có và áp dụng tất cả các resource của chúng vào container mới. - Đóng gói tự động
Bạn cung cấp cho Kubernetes một cluster gồm các node mà nó có thể sử dụng để chạy các tác vụ được đóng gói (containerized task). Bạn cho Kubernetes biết mỗi container cần bao nhiêu CPU và bộ nhớ (RAM). Kubernetes có thể điều phối các container đến các node để tận dụng tốt nhất các resource của bạn. - Tự phục hồi
Kubernetes khởi động lại các containers bị lỗi, thay thế các container, xoá các container không phản hồi lại cấu hình health check do người dùng xác định và không cho các client biết đến chúng cho đến khi chúng sẵn sàng hoạt động. - Quản lý cấu hình và bảo mật
Kubernetes cho phép bạn lưu trữ và quản lý các thông tin nhạy cảm như: password, OAuth token và SSH key. Bạn có thể triển khai và cập nhật lại secret và cấu hình ứng dụng mà không cần build lại các container image và không để lộ secret trong cấu hình stack của bạn.
Kubernetes không phải là gì?
Kubernetes không phải là một hệ thống PaaS (Nền tảng như một Dịch vụ) truyền thống, toàn diện. Do Kubernetes hoạt động ở tầng container chứ không phải ở tầng phần cứng, nó cung cấp một số tính năng thường áp dụng chung cho các dịch vụ PaaS, như triển khai, nhân rộng, cân bằng tải, ghi nhật ký và giám sát. Tuy nhiên, Kubernetes không phải là cấu trúc nguyên khối và các giải pháp mặc định này là tùy chọn và có thể cắm được (pluggable).
Kubernetes:
- Không giới hạn các loại ứng dụng được hỗ trợ. Kubernetes nhằm mục đích hỗ trợ một khối lượng công việc cực kỳ đa dạng, bao gồm cả stateless, stateful và xử lý dữ liệu. Nếu một ứng dụng có thể chạy trong một container, nó sẽ chạy rất tốt trên Kubernetes.
- Không triển khai mã nguồn và không build ứng dụng của bạn. Quy trình CI/CD được xác định bởi tổ chức cũng như các yêu cầu kỹ thuật.
- Không cung cấp các service ở mức ứng dụng, như middleware (ví dụ, các message buses), các framework xử lý dữ liệu (ví dụ, Spark), cơ sở dữ liệu (ví dụ, MySQL), bộ nhớ cache, cũng như hệ thống lưu trữ của cluster (ví dụ, Ceph). Các thành phần như vậy có thể chạy trên Kubernetes và/hoặc có thể được truy cập bởi các ứng dụng chạy trên Kubernetes thông qua các cơ chế di động, chẳng hạn như Open Service Broker.
- Không bắt buộc các giải pháp ghi lại nhật ký (logging), giám sát (monitoring) hoặc cảnh báo (alerting). Nó cung cấp một số sự tích hợp như proof-of-concept, và cơ chế để thu thập và xuất các số liệu.
- Không cung cấp, không bắt buộc một cấu hình ngôn ngữ/hệ thống (ví dụ: Jsonnet). Nó cung cấp một API khai báo có thể được targeted bởi các hình thức khai báo tùy ý.
- Không cung cấp cũng như áp dụng bất kỳ cấu hình toàn diện, bảo trì, quản lý hoặc hệ thống tự phục hồi.
- Ngoài ra, Kubernetes không phải là một hệ thống điều phối đơn thuần. Trong thực tế, nó loại bỏ sự cần thiết của việc điều phối. Định nghĩa kỹ thuật của điều phối là việc thực thi một quy trình công việc được xác định: đầu tiên làm việc A, sau đó là B rồi sau chót là C. Ngược lại, Kubernetes bao gồm một tập các quy trình kiểm soát độc lập, có thể kết hợp, liên tục điều khiển trạng thái hiện tại theo trạng thái mong muốn đã cho. Nó không phải là vấn đề làm thế nào bạn có thể đi được từ A đến C. Kiểm soát tập trung cũng không bắt buộc. Điều này dẫn đến một hệ thống dễ sử dụng hơn, mạnh mẽ hơn, linh hoạt hơn và có thể mở rộng.
Tiếp theo là gì
- Xem thêm về các thành phần của Kubernetes
- Sẵn sàng bắt đầu?
2 - Kiến Trúc Cluster
Các khái niệm về kiến trúc của Kubernetes.
Một cụm Kubernetes bao gồm một bảng điều khiển trung tâm (control plane) và một nhóm các máy chạy các ứng dụng đã được container hóa, gọi là node. Mỗi cụm Kubernetes cần ít nhất một node như vậy để chạy Pod.
Các máy công nhân (worker node) chạy Pod, chính là các thành phần của ứng dụng. Bảng điều khiển trung tâm quản lý các máy này cũng như Pod trong cụm. Để đảm bảo khả năng chịu lỗi và tính khả dụng cao, bảng điều khiển trung tâm thường được chạy trên nhiều máy đồng thời, và cụm cũng được chạy với nhiều node.
Tài liệu này phác thảo các thành phần khác nhau mà bạn cần có để có một cụm Kubernetes hoàn chỉnh và hoạt động.

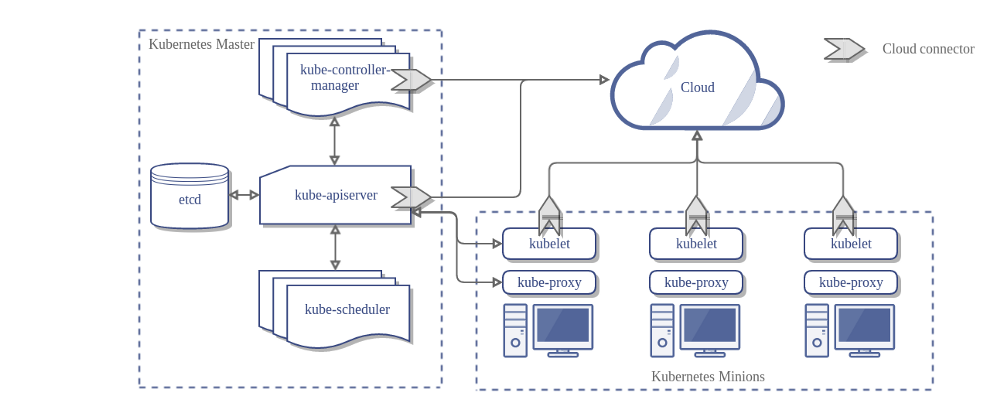
Hình 1. Các thành phần của cụm Kubernetes.
Chi tiết về kiến trúc
Hình 1 mô tả kiến trúc cơ bản của một cụm Kubernetes. Các thành phần thực tế có thể có sự thay đổi tùy thuộc vào cài đặt và yêu cầu của cụm.
Trong sơ đồ, mỗi node chạy một kube-proxy. Bạn cần một thành phần network proxy ở mỗi node để đảm bảo Service API và các tính năng liên quan hoạt động trong mạng của cụm. Tuy nhiên, một số network plugin cung cấp proxy của bên thứ ba. Khi bạn sử dụng loại plugin đó, node trong cụm không cần thiết phải chạy kube-proxy.
Bảng điều khiển trung tâm (Control plane)
Các thành phần của bảng điều khiển trung tâm có vai trò đưa ra các quyết định tổng thể trong cụm (ví dụ: lập lịch và phân phối), cũng như phát hiện và phản hồi các sự kiện xảy ra trong cụm (ví dụ: khởi tạo một pod khi phát hiện trường replicas của Deployment không đúng).
Các thành phần của bảng điều khiển trung tâm có thể chạy trên bất cứ máy nào trong cụm. Tuy nhiên, để đơn giản, các script cài đặt thường khởi tạo và chạy tất cả các thành phần của bảng điều khiển trên cùng một máy, và các containers ứng dụng sẽ không được chạy trên máy đó.
Xem thêm Tạo một cụm khả dụng cao với kubeadm về hướng dẫn cách cài đặt bảng điều khiển trung tâm chạy đồng thời trên nhiều máy.
kube-apiserver
API server là một thành phần của Kubernetes control plane, được dùng để đưa ra Kubernetes API. API server là front end của Kubernetes control plane.
Thực thi chính của API server là kube-apiserver. kube-apiserver được thiết kế để co giãn theo chiều ngang — có nghĩa là nó co giãn bằng cách triển khai thêm các thực thể. Bạn có thể chạy một vài thực thể của kube-apiserver và cân bằng lưu lượng giữa các thực thể này.
etcd
Key value store nhất quán (consistent) và sẵn sàng cao (highly-available) được sử dụng như một kho lưu trữ của Kubernetes cho tất cả dữ liệu của cluster.
Nếu Kubernetes cluster của bạn sử dụng etcd như kho lưu trữ của nó, chắc chắn bạn có một kế hoạch back up cho những dữ liệu này.
Bạn có thể tìm thêm thông tin chi tiết về etcd tại documentation.
kube-scheduler
Thành phần của Control Plane, được dùng để giám sát việc tạo những pod mới mà chưa được chỉ định vào node nào, và chọn một node để chúng chạy trên đó.
Những yếu tố trong những quyết định lập lịch bao gồm những yêu cầu về tài nguyên, những đòi hỏi về phần cứng/phần mềm/chính sách, những thông số về affinity và anti-affinity, dữ liệu tại chỗ (data locality), nhiễu inter-workload và thời hạn (deadline).
kube-controller-manager
Thành phần control plane chạy các tiến trình controller.
Về mặt logic, mỗi controller là một tiến trình riêng biệt, nhưng để giảm độ phức tạp, tất cả đều được biên dịch thành một binary duy nhất và chạy trong một tiến trình duy nhất.
Có rất nhiều controller khác nhau, một số có thể kể đến như:
- Node controller: Chịu trách nhiệm theo dõi và phản hồi khi có node gặp sự cố.
- Job controller: Theo dõi Job object, đồng thời tạo Pod để chạy các task và đảm bảo task hoàn thành.
- EndpointSlice controller: Điền thông tin vào các đối tượng EndpointSlice (để cung cấp liên kết giữa Service và Pod).
- ServiceAccount controller: Tạo ServiceAccount mặc định cho namespace mới.
và còn nhiều controller khác nữa.
cloud-controller-manager
Đây là một chức năng control plane của Kubernetes cho phép nhúng logic điều khiển các cloud-specific(AWS Lambda/Azure Functions). Cloud controller manager cho phép bạn liên kết cluster của mình với API của cloud provider, đồng thời tách biệt các thành phần tương tác với nền tảng đám mây đó ra khỏi các thành phần chỉ tương tác với cụm của bạn.Cloud controller manager chỉ chạy các controller cụ thể dành cho nhà cung cấp dịch vụ cloud bạn đang sử dụng. Nếu bạn chạy Kubernetes trên phần cứng của bạn, hoặc trong môi trường thử nghiệm trên PC của bạn, cụm sẽ không chứa bất kỳ cloud controller manager nào.
Tương tự như kube-controller-manager, cloud-controller-manager kết hợp nhiều vòng lặp điều khiển, độc lập về mặt logic, được tổng hợp lại thành một tập nhị phân, và bạn có thể chạy như một tiến trình đơn. Bạn có thể mở rộng theo chiều ngang (chạy thêm một tiến trình khác tương tự) để tăng hiệu suất hoặc giúp tăng chịu lỗi hệ thống.
Một số controller sau có thể có sự phụ thuộc vào nhà cung cấp cloud:
- Node controller: Để kiểm tra nhà cung cấp cloud, xác định xem một nút đã bị xóa trong trên cloud sau khi nó ngừng phản hồi hay chưa.
- Route controller: Để thiết lập các route mạng trong cơ sở hạ tầng cloud.
- Service controller: Để khởi tạo, cập nhật và xóa load balancer tương ứng của nhà cung cấp cloud.
Các thành phần trên máy node
Các thành phần trên node chạy trong tất cả các node của cụm, quản lý các pod đang chạy, và cung cấp môi trường runtime của Kubernetes.
kubelet
Một agent chạy trên mỗi node nằm trong cluster. Nó giúp đảm bảo rằng các containers đã chạy trong một pod.
Kubelet sẽ nhận một tập các PodSpecs (đặc tính của Pod) được cung cấp thông qua các cơ chế khác nhau và bảo đảm rằng containers được mô tả trong những PodSpecs này chạy ổn định và khỏe mạnh. Kubelet không quản lý những containers không được tạo bởi Kubernetes.
kube-proxy (optional)
kube-proxy là một network proxy chạy trên mỗi node trong cluster, thực hiện một phần Kubernetes Service.
kube-proxy duy trình network rules trên các node. Những network rules này cho phép kết nối mạng đến các pods từ trong hoặc ngoài cluster.
Kube-proxy sử dụng lớp packet filtering của hệ điều hành nếu có sẵn. Nếu không thì kube-proxy sẽ tự điều hướng network traffic.
Nếu bạn sử dụng network plugin có hỗ trợ triển khai chuyển tiếp gói tin cho Service, đồng thời có cung cấp các tính năng tương tự kube-proxy, bạn sẽ không cần cài đặt kube-proxy trên các node trong cụm.
Container runtime
Một thành phần cơ bản mà ủy quyền cho Kubernetes chạy các container một cách có hiệu quả. Nó chịu trách nhiệm quản lý việc thực thi và vòng đời của các container trong môi trường Kubernetes.
Kubernetes hỗ trợ các container runtime như containerd, CRI-O, và bất kỳ những triển khai nào của Kubernetes CRI (Container Runtime Interface).
Addons
Addons sử dụng Kubernetes resource như (DaemonSet,
Deployment, vv) để triển khai các chức năng của cụm. Vì đó là các chức năng ở cấp độ toàn cụm, các namespace resource được sử dụng bởi chúng sẽ thuộc về kube-system namespace.
Danh sách một số các addon được liệt kê dưới đây; nếu bạn muốn xem danh sách đầy đủ, có thể tìm kiếm thêm tại Addons.
DNS
Khác với hầu hết các addon là phần mở rộng không bắt buộc, mọi cụm Kubernetes đều nên có cluster DNS. Rất nhiều ví dụ hoạt động phụ thuộc vào nó.
Cluster DNS là một DNS server, bổ sung thêm cho các DNS server khác hoạt động trong môi trường của bạn. Nó chủ yếu phụ vụ các bản ghi DNS cho Kubernetes service.
Các container khởi tạo bởi Kubernetes mặc định thêm DNS server này vào danh sách DNS của chúng.
Web UI (Dashboard)
Dashboard là một UI trên nên web của cụm Kubernetes. Nó cho phép người dùng quản lý và khắc phục sự cố của bản thân cụm, cũng như những ứng dụng chạy trên cụm đó.
Container resource monitoring
Container Resource Monitoring ghi lại các thông số của container dưới dạng time-series trong một database tập trung, đồng thời cung cấp một UI để duyệt những dữ liệu đó.
Cluster-level Logging
Cơ chế cluster-level logging chịu trách nhiệm lưu trữ log của container ở một kho lưu trữ log tập trung, đồng thời cung cấp tính năng tìm kiếm/duyệt các dữ liệu đó.
Network plugins
Network plugins là những phần mềm triển khai Container Network Interface (CNI). Chúng chịu trách nhiệm phân bổ địa chỉ IP cho pod và đảm bảo kết nối giữa các pod trong cụm.
Các biến thể trong kiến trúc
Trong khi các thành phần chính của Kubernetes là cố định, cách chúng được triển khai và quản lý có thể có sự khác biệt. Hiểu về những biến thể đó rất quan trọng để thiết kế và duy trì các cụm Kubernetes đáp ứng các nhu cầu vận hành cụ thể.
Control plane deployment options
Các thành phần của bảng điều khiển trung tâm có thể được triển khai bằng một số cách:
Triển khai truyền thống: Các thành phần chạy trực tiếp trên các máy tính hoặc VM cụ thể được chỉ định, thường được quản lý bởi systemd.
Static Pod: Các thành phần được triển khai như là các static Pod, được quản lý bởi kubelet trên các node cụ thể. Đây là cách làm của công cụ như kubeadm.
Self-hosted: Bảng điều khiển trung tâm chạy như là Pod trong chính cụm Kubernetes, được quản lý bởi Deployment và StatefulSet hoặc các resource khác của Kubernetes.
Managed Kubernetes service: Các nhà cung cấp cloud sẽ trừu tượng hóa bảng điều khiển trung tâm, thay mặt người dùng quản lý nó như một phần của dịch vụ mà họ cung cấp.
Cân nhắc về vị trí phân phối Workload
Việc phân phối workload, bao gồm cả các thành phần của bảng điều khiển trung tâm phụ thuộc nhiều yếu tố bao gồm kích thước cụm, yêu cầu về hiệu suất và chính sách hoạt động:
- Trên cụm có kích thước nhỏ hoặc môi trường phát triển, các thành phần của bảng điều khiển trung tâm và workload của người dùng có thể chạy trên cùng node.
- Trên môi trường production, các node cụ thể được chỉ định riêng cho các thành phần của bảng điều khiển trung tâm, tách biệt khỏi workload của người dùng.
- Một số tổ chức chạy các addon quan trọng hoặc công cụ theo dõi trên node chạy các thành phần của bảng điều khiển trung tâm.
Cluster management tools
Các công cụ như kubeadm, kops, hay Kubespray cung cấp các cách tiếp cận khác nhau để triển khai và quản lý cụm, mỗi cách có phương pháp bố trí và quản lý thành phần riêng.
Tính linh hoạt của kiến trúc Kubernetes cho phép các tổ chức tùy chỉnh cụm của mình theo nhu cầu cụ thể, cân bằng các yếu tố như độ phức tạp của hoạt động, hiệu suất và chi phí quản lý.
Tùy chỉnh và khả năng mở rộng
Kiến trúc Kubernetes cho phép nhiều tùy chỉnh:
- Custom scheduler có thể được triển khai cùng với scheduler mặc định của Kubernetes hoặc thay thế hoàn toàn nó.
- API server có thể được mở rộng với CustomResourceDefinitions và API Aggregation.
- Các nhà cung cấp Cloud có thể tích hợp sâu với Kubernetes thông qua cloud-controller-manager.
Tính linh hoạt của kiến trúc Kubernetes cho phép các tổ chức điều chỉnh cụm của họ cho các mục đích cụ thể, cân bằng giữa nhiều yếu tố như độ phức tạp vận hành, hiệu suất, và chi phí quản lý.
Tiếp theo là gì
Tìm hiểu thêm về:
- Nodes và cách giao tiếp với bảng điều khiển trung tâm.
- Kubernetes controllers.
- kube-scheduler - scheduler mặc định của Kubernetes.
- Tài liệu về Etcd.
- Một số container runtime của Kubernetes.
- Tích hợp với các nhà cung cấp Cloud thông qua cloud-controller-manager.
- kubectl command.
2.1 - Leases
Trong các hệ thống phân tán, Kubernetes sử dụng cơ chế leases (giữ quyền tạm thời) để khóa tài nguyên dùng chung và điều phối hoạt động giữa các thành phần trong cụm. Trong Kubernetes, lease được biểu diễn bằng các đối tượng Lease thuộc API group coordination.k8s.io API Group, Những đối tượng này đóng vai trò quan trọng trong hệ thống, ví dụ như theo dõi trạng thái node (heartbeat) và cơ chế bầu chọn leader giữa các thành phần nội bộ.
Node heartbeats
Kubernetes sử dụng Lease API để truyền tín hiệu heartbeat từ kubelet về Kubernetes API server. Với mỗi đối tượng Node, sẽ có một đối tượng Lease tương ứng (có cùng tên) nằm trong namespace kube-node-lease. Ở tầng bên dưới, mỗi lần kubelet gửi heartbeat thực chất là một lệnh update lên đối tượng Lease, cập nhật trường spec.renewTime. Control plane của Kubernetes sẽ dựa vào dấu thời gian trong trường này để xác định node đó còn hoạt động hay không.
Xem Node Lease objects để biết thêm chi tiết.
Leader election
Kubernetes cũng sử dụng Lease để đảm bảo rằng chỉ một phiên bản duy nhất của một thành phần có thể hoạt động tại một thời điểm.
Cơ chế này được áp dụng cho các thành phần của control plane như kube-controller-manager và kube-scheduler trong các cấu hình HA (High Availability) — nơi chỉ một phiên bản của thành phần đó được phép hoạt động chính, còn các phiên bản còn lại sẽ ở chế độ chờ.
Đọc thêm tại coordinated leader election để tìm hiểu cách Kubernetes sử dụng Lease API để chọn phiên bản nào sẽ đóng vai trò leader.
API server identity
TRẠNG THÁI TÍNH NĂNG:
Kubernetes v1.26 [beta](enabled by default)Từ phiên bản Kubernetes v1.26, mỗi kube-apiserver sẽ sử dụng Lease API để công bố danh tính của mình với phần còn lại của hệ thống.Mặc dù việc này chưa mang lại lợi ích trực tiếp, nhưng nó cung cấp một cơ chế để các thành phần khác có thể phát hiện được có bao nhiêu phiên bản kube-apiserver đang hoạt động trong control plane. Việc tồn tại các Lease của kube-apiserver giúp chuẩn bị cho các tính năng trong tương lai, nơi các kube-apiserver có thể cần phối hợp hoạt động với nhau.
Bạn có thể kiểm tra các Lease này trong namespace kube-system, với tên theo dạng apiserver-<sha256-hash>. Hoặc sử dụng label để lọc apiserver.kubernetes.io/identity=kube-apiserver:
kubectl -n kube-system get lease -l apiserver.kubernetes.io/identity=kube-apiserver
NAME HOLDER AGE
apiserver-07a5ea9b9b072c4a5f3d1c3702 apiserver-07a5ea9b9b072c4a5f3d1c3702_0c8914f7-0f35-440e-8676-7844977d3a05 5m33s
apiserver-7be9e061c59d368b3ddaf1376e apiserver-7be9e061c59d368b3ddaf1376e_84f2a85d-37c1-4b14-b6b9-603e62e4896f 4m23s
apiserver-1dfef752bcb36637d2763d1868 apiserver-1dfef752bcb36637d2763d1868_c5ffa286-8a9a-45d4-91e7-61118ed58d2e 4m43s
Chuỗi SHA256 hash được sử dụng trong tên của đối tượng Lease được tính dựa trên hostname của hệ điều hành mà kube-apiserver nhìn thấy. Do đó, mỗi kube-apiserver cần được cấu hình với một hostname duy nhất trong cụm Kubernetes để tránh xung đột.
Khi có một instance mới của kube-apiserver được khởi động và sử dụng cùng hostname với một instance trước đó, nó sẽ tiếp quản Lease đã có sẵn bằng cách ghi đè holder identity, thay vì tạo một Lease mới.Bạn có thể kiểm tra hostname mà kube-apiserver đang sử dụng bằng cách tra nhãn kubernetes.io/hostname trên node hoặc pod tương ứng:
kubectl -n kube-system get lease apiserver-07a5ea9b9b072c4a5f3d1c3702 -o yaml
apiVersion: coordination.k8s.io/v1
kind: Lease
metadata:
creationTimestamp: "2023-07-02T13:16:48Z"
labels:
apiserver.kubernetes.io/identity: kube-apiserver
kubernetes.io/hostname: master-1
name: apiserver-07a5ea9b9b072c4a5f3d1c3702
namespace: kube-system
resourceVersion: "334899"
uid: 90870ab5-1ba9-4523-b215-e4d4e662acb1
spec:
holderIdentity: apiserver-07a5ea9b9b072c4a5f3d1c3702_0c8914f7-0f35-440e-8676-7844977d3a05
leaseDurationSeconds: 3600
renewTime: "2023-07-04T21:58:48.065888Z"
Các Lease đã hết hạn từ những kube-apiserver không còn tồn tại sẽ được thu gom tự động (garbage collect) bởi các kube-apiserver mới sau 1 giờ.
Bạn có thể tắt cơ chế Lease định danh của API server bằng cách vô hiệu hóa feature gate APIServerIdentity. Xem thêm tại feature gate.
Workloads
Bạn có thể tự định nghĩa và sử dụng Lease cho chính workload của mình.
Ví dụ: bạn có thể chạy một controller tùy chỉnh, trong đó một bản sao chính (primary hoặc leader) sẽ thực hiện các thao tác mà các bản sao còn lại không thực hiện.
Bạn định nghĩa một đối tượng Lease để các bản sao của controller có thể chọn hoặc bầu chọn ra leader, sử dụng Kubernetes API để phối hợp hoạt động.
Nếu bạn sử dụng Lease, cách thực hiện tốt là đặt tên Lease sao cho dễ liên kết với sản phẩm hoặc thành phần sử dụng nó.
Ví dụ: nếu bạn có một thành phần tên là Example Foo, thì nên đặt Lease là example-foo.
Nếu người vận hành cluster hoặc người dùng cuối có thể triển khai nhiều phiên bản của cùng một thành phần, hãy chọn một tiền tố tên riêng biệt và áp dụng một cơ chế (chẳng hạn như hash của tên Deployment) để tránh trùng tên Lease.
Bạn cũng có thể sử dụng một cách tiếp cận khác, miễn là đạt được mục tiêu chung: các phần mềm khác nhau không gây xung đột với nhau khi sử dụng Lease.
2.2 - Các khái niệm nền tảng của Cloud Controller Manager
Khái niệm Cloud Controller Manager (CCM) (để tránh nhầm lẫn với bản binary build cùng tên) được định nghĩa riêng biệt để cho phép các bên cung cấp dịch vụ cloud và thành phần chính của Kubernetes phát triển độc lập với nhau. CCM chạy đồng thời với những thành phần khác thuộc máy chủ của một cluster như Controller Manager của Kubernetes, API server, và Scheduler. Nó cũng có thể đóng vai trò như một addon cho Kubernetes.
Cloud Controller Manager này được thiết kế dựa trên cơ chế plugin nhằm cho phép các bên Cloud Provider có thể tích hợp với Kubernetes một cách dễ dàng thông qua các plugin này. Đã có những bản kế hoạch được thiết kế sẵn nhằm mục đích hỗ trợ những cloud provider thay đổi từ mô hình cũ sang mô hình mới đi chung với CCM.
Tài liệu này thảo luận về những khái niệm đằng sau một CCM và đưa ra những chi tiết về chức năng liên quan của nó.
Dưới đây là kiến trúc của một Kubernetes cluster khi không đi cùng với Cloud Controller Manager:
Thiết kế
Trong sơ đồ trên, Kubernetes và nhà cung cấp dịch vụ cloud được tích hợp thông qua một số thành phần sau:
- Kubelet
- Kubernetes Controller Manager
- Kubernetes API server
CCM hợp nhất tất cả các logic phụ thuộc trên một nền tàng Cloud từ 3 thành phần trên để tạo thành một điểm tích hợp duy nhất với hệ thống Cloud. Sơ đồ kiến trúc khi đi kèm với CCM sẽ trở thành:
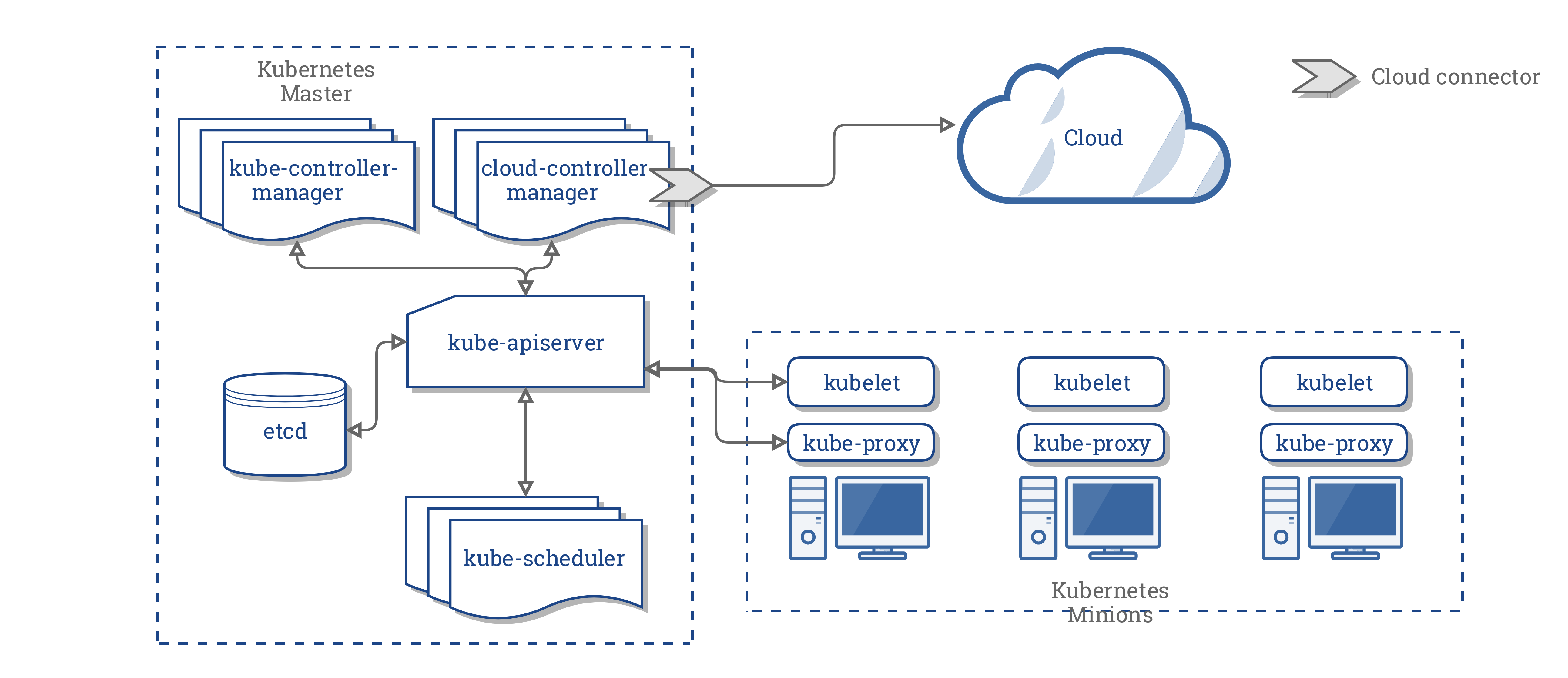
Các thành phần của CCM
Cloud Controller Manager phân nhỏ một số chức năng của Kubernetes controller manager (KCM) và chạy nó như một tiến trình tách biệt. Cụ thể hơn, nó phân nhỏ những controller trong Kubernetes Controller Manager phụ thuộc vào Cloud. Kubernetes Controller Manager sẽ có những controller nhỏ hơn:
- Node controller
- Volume controller
- Route controller
- Service controller
Tại phiên bản 1.9, CCM thực hiện chạy những controller sau từ trong danh sách trên:
- Node controller
- Route controller
- Service controller
Lưu ý:
Volume controller được bỏ ra khỏi Cloud Controller Manager. Do độ phức tạp lớn ảnh hướng và sẽ tốn nhiều thời gian cũng như nhân lực không đáp ứng đủ cho việc tách hẳn tầng logic liên quan tới Volume từ những bên cung cấp dịch vụ, và quyết định cuối cùng là sẽ không triển khai quản lý Volume như một phần của CCM.Kết hoạch ban đầu của dự án là hỗ trợ Volume sử dụng Cloud Controller Manager để áp dụng những Flex Volume linh hoạt nhằm dễ dàng tích hợp bổ sung thêm. Tuy nhiên, một giải pháp khác cũng đang được lên kế hoạch để thay thế Flex Volume được biết là CSI.
Sau khi xem xét về khía cạnh này, chúng tôi quyết định sẽ có một khoảng thời gian nghỉ trước khi CSI trở nên sẵn sàng cho việc sử dụng.
Chức năng của Cloud Controller Manager
CCM thừa hưởng những tính năng của nó từ các thành phần trong Kubernetes phụ thuộc vào các Cloud Provider. Phần kế tiếp sẽ giới thiệu những thành phần này.
1. Kubernetes Conntroller Manager
Phần lớn các tính năng của CCM bắt nguồn từ Kubernetes controller manager. Như đã đề cập ở phần trước, CCM bao gồm:
- Node controller
- Route controller
- Service controller
Node controller
Node controller có vai trò khởi tạo một Node bằng cách thu thập thông tin về những Node đang chạy trong cluster từ các cloud provider.
Node controller sẽ thực hiện những chức năng sau:
- Khởi tạo một Node với các nhãn region/zone.
- Khởi tạo một Node với những thông tin được cung cấp từ cloud, ví dụ như loại máy và kích cỡ.
- Thu thập địa chỉ mạng của Node và hostname.
- Trong trường hợp một Node không có tín hiệu phản hồi, Node controller sẽ kiểm tra xem Node này có thực sự xóa khỏi hệ thống cloud hay chưa. Nếu Node đó không còn tồn tại trên cloud, controller sẽ xóa Node đó khỏi Kubernetes cluster.
Route controller
Route controller đóng vai trò cấu hình định tuyến trong nằm trong hệ thống cloud để các container trên các Node khác nhau trong Kubernetes cluster có thể giao tiếp với nhau. Route controller hiện chỉ đáp ứng được cho các Google Compute Engine cluster.
Service controller
Service controller lắng nghe các sự kiện tạo mới, cập nhật và xoá bỏ một service. Dựa trên trạng thái hiện tại của các vụ trên Kubernetes, nó cấu hình các dịch vụ cân bằng tải trên cloud (như ELB của AWS, Google Load Balancer, hay Oracle Cloud Infrastructure LB) nhằm phản ánh trạng thái của các Service trên Kubernetes. Ngoài ra, nó đảm bảo những service backends cho các dịch vụ cần bằng tải trên cloud được cập nhật
2. Kubelet
Node controller bao gồm một số tính năng phụ thuộc vào tầng cloud của Kubelet. Trước khi có CCM, Kubelet đảm nhận vai trò khởi tạo một Node với thông tin chi tiết từ cloud như địa chỉ IP, region hay instance type. Với CCM, vai trò này được CCM đảm nhận thay cho Kubelet.
Với mô hình mới này, Kubelet sẽ khởi tạo một Node nhưng không đi kèm với những thông tin từ cloud. Tuy nhiên, nó sẽ thêm vào một dấu Taint để đánh dấu Node sẽ không được lập lịch cho tới khi CCM khởi tạo xong Node này với những thông tin cụ thể cung cấp từ Cloud, sau đó nó sẽ xóa những dấu chờ này.
Cơ chế Plugin
CCM sử dụng interface trong ngôn ngữ Go cho phép triển khai trên bất kì hệ thống cloud nào cũng có thể plugged in. Cụ thể hơn, nó sử dụng CloudProvider Interface được định nghĩa ở đây.
Cách triển khai của bốn controller được nêu ở trên, và một số được thực hiện như giao diện chung cho các bên cung cấp dịch vụ cloud, sẽ ở trong lõi (core) của Kubernetes. Việc triển khai dành riêng cho từng cloud provider sẽ được xây dựng bên ngoài lõi (core) và triển khai các giao diện được xác định bên trong lõi.
Để biết thêm chỉ tiết, xem Cloud Controller Manager.
Phân quyền
Phần này sẽ phân nhỏ quyền truy cập cần có cho các API object cung cấp bởi CCM để thực hiện những hành động của nó.
Node controller
Node controller chỉ hoạt động với các Node. Nó yêu cầu đầy đủ quyền truy cập bao gồm get, list, create, update, patch, watch, và delete một Node.
v1/Node:
- Get
- List
- Create
- Update
- Patch
- Watch
- Delete
Route controller
Route controller lắng nghe sự kiện tạo ra các Node và cấu hình các Route tương ứng. Nó yêu cầu có quyền truy cập get tới các đối Node.
v1/Node:
- Get
Service controller
Service controller lắng nghe các sự kiện khởi tạo, cập nhật và xóa bỏ một Service và cấu hình những endpoint phù hợp.
Để truy cập các Service, nó cần quyền list, và watch. Để cập nhật Service, nó sẽ cần patch và update.
Để thiết lập các endpoint cho các Service, nó cần quyền create, list, get, watch, và update.
v1/Service:
- List
- Get
- Watch
- Patch
- Update
Các vấn đề khác
Việc triển khai lõi của CCM yêu cầu cần có quyền tạo mới sự kiện và đảm bảo quyền thực thi một số hành động, nó cần có quyền tạo các Service Accounts
v1/Event:
- Create
- Patch
- Update
v1/ServiceAccount:
- Create
Với RBAC ClusterRole, CCM cần có ClusterRole tối thiểu:
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: cloud-controller-manager
rules:
- apiGroups:
- ""
resources:
- events
verbs:
- create
- patch
- update
- apiGroups:
- ""
resources:
- nodes
verbs:
- "*"
- apiGroups:
- ""
resources:
- nodes/status
verbs:
- patch
- apiGroups:
- ""
resources:
- services
verbs:
- list
- patch
- update
- watch
- apiGroups:
- ""
resources:
- serviceaccounts
verbs:
- create
- apiGroups:
- ""
resources:
- persistentvolumes
verbs:
- get
- list
- update
- watch
- apiGroups:
- ""
resources:
- endpoints
verbs:
- create
- get
- list
- watch
- update
Các nhà cung cấp đã triển khai
Sau đây là danh sách các nhà cung cấp dịch vụ cloud đã triển khai CCM:
Quản lý Cluster
Hướng dẫn chi tiết cho việc cấu hình và chạy CCM được cung cấp tại đây.
2.3 - Kubernetes - Khả năng tự phục hồi (Self-Healing)
Kubernetes được thiết kế với khả năng tự phục hồi giúp duy trì tình trạng khỏe mạnh và tính khả dụng của các workload. Nó tự động thay thế các container bị lỗi, lập lịch lại các workload khi node trở nên không khả dụng, và đảm bảo rằng trạng thái mong muốn của hệ thống được duy trì.
Khả năng tự phục hồi
-
Khởi động lại ở cấp độ container: Nếu một container bên trong Pod bị lỗi, Kubernetes sẽ khởi động lại nó dựa trên
restartPolicy. -
Thay thế replica: Nếu một Pod trong Deployment hoặc StatefulSet bị lỗi, Kubernetes sẽ tạo một Pod thay thế để duy trì số lượng replica được chỉ định. Nếu một Pod thuộc DaemonSet bị lỗi, control plane sẽ tạo một Pod thay thế để chạy trên cùng node đó.
-
Phục hồi persistent storage: Nếu một node đang chạy Pod với PersistentVolume (PV) được gắn kết, và node đó bị lỗi, Kubernetes có thể gắn lại volume vào Pod mới trên node khác.
-
Cân bằng tải cho Service: Nếu một Pod đằng sau Service bị lỗi, Kubernetes sẽ tự động loại bỏ nó khỏi endpoint của Service để chỉ định tuyến traffic đến các Pod khỏe mạnh.
Dưới đây là một số thành phần chính cung cấp khả năng tự phục hồi của Kubernetes:
-
kubelet: Đảm bảo rằng các container đang chạy, và khởi động lại những container bị lỗi.
-
ReplicaSet, StatefulSet và DaemonSet controller: Duy trì số lượng replica Pod mong muốn.
-
PersistentVolume controller: Quản lý việc gắn kết và tháo gỡ volume cho các stateful workload.
Những điều cần cân nhắc
-
Lỗi Storage: Nếu một persistent volume trở nên không khả dụng, có thể cần các bước phục hồi thủ công.
-
Lỗi Ứng dụng: Kubernetes có thể khởi động lại container, nhưng các vấn đề ứng dụng cơ bản phải được giải quyết riêng biệt.
Tiếp theo là gì
- Đọc thêm về Pod
- Tìm hiểu về Kubernetes Controller
- Khám phá PersistentVolume
- Đọc về node autoscaling. Node autoscaling cũng cung cấp khả năng tự phục hồi tự động nếu hoặc khi các node bị lỗi trong cluster của bạn.
2.4 - Proxy Đa Phiên Bản (Mixed Version Proxy)
TRẠNG THÁI TÍNH NĂNG:
Kubernetes v1.28 [alpha](disabled by default)Kubernetes 1.35 giới thiệu một tính năng alpha cho phép API Server proxy các yêu cầu tài nguyên đến các API server ngang hàng khác. Tính năng này đặc biệt hữu ích khi trong một cụm có nhiều API server đang chạy các phiên bản Kubernetes khác nhau (ví dụ: trong quá trình nâng cấp cụm kéo dài sang phiên bản mới).
Điều này giúp quản trị viên của cluster cấu hình các cluster có độ sẵn sàng cao (high availability) có thể được nâng cấp một cách an toàn hơn, bằng cách chuyển hướng các yêu cầu tài nguyên (trong thời gian nâng cấp) đến đúng kube-api server. Cơ chế proxy này giúp người dùng tránh gặp lỗi 404 (Not Found) không mong muốn do quá trình nâng cấp gây ra.
Cơ chế này được gọi là Proxy Đa Phiên Bản.
Bật tính năng Proxy Đa Phiên Bản
Đảm bảo rằng cờ feature gate UnknownVersionInteroperabilityProxy đã được bật khi khởi động
API Server:
kube-apiserver \
--feature-gates=UnknownVersionInteroperabilityProxy=true \
# các tham số dòng lệnh bắt buộc cho tính năng này
--peer-ca-file=<đường dẫn đến CA cert của kube-apiserver>
--proxy-client-cert-file=<đường dẫn đến chứng chỉ proxy của aggregator>,
--proxy-client-key-file=<đường dẫn đến khóa proxy của aggregator>,
--requestheader-client-ca-file=<đường dẫn đến CA cert của aggregator>,
# requestheader-allowed-names có thể để trống để chấp nhận mọi Common Name
--requestheader-allowed-names=<các Common Name hợp lệ để xác minh chứng chỉ proxy client>,
# các cờ tuỳ chọn cho tính năng này
--peer-advertise-ip=<Địa chỉ IP của kube-apiserver này để peer sử dụng khi proxy> --peer-advertise-port=<Cổng mà kube-apiserver này mở để peer sử dụng khi proxy>
# …và các cờ khác như thường lệ
Kết nối và xác thực giữa các API server
-
API server nguồn tái sử dụng các cờ xác thực client cho API server hiện có là
--proxy-client-cert-filevà--proxy-client-key-fileđể trình bày danh tính của nó, danh tính này sẽ được kube-apiserver đích (destination kube-apiserver) xác minh. API server đích sẽ xác thực kết nối từ phía đối tác dựa trên cấu hình được chỉ định thông qua tham số dòng lệnh--requestheader-client-ca-file. -
Để xác thực chứng chỉ phục vụ (serving cert) của API server đích, bạn cần cấu hình một gói chứng chỉ CA bằng cách cung cấp tham số dòng lệnh
--peer-ca-filecho API server nguồn.
Cấu hình kết nối tới peer API server
Để khai báo địa chỉ mạng của một API server mà các peer sẽ sử dụng để proxy yêu cầu, sử dụng các tham số --peer-advertise-ip và --peer-advertise-port, hoặc khai báo trong tệp cấu hình của API server.
Nếu không khai báo các cờ này, kube-apiserver sẽ mặc định sử dụng giá trị từ --advertise-address hoặc --bind-address. Nếu các tham số này cũng không được cấu hình, địa chỉ giao diện mạng mặc định của máy chủ sẽ được dùng.
Cơ chế proxy giữa các phiên bản khác nhau
Khi proxy đa phiên bản được bật, aggregation layer sẽ tải một bộ lọc đặc biệt với các hành vi sau:
- Khi một API server nhận được yêu cầu tài nguyên mà nó không thể xử lý (do chưa hỗ trợ API đó hoặc API bị tắt), nó sẽ tìm cách proxy yêu cầu đến một API server ngang hàng có thể xử lý yêu cầu đó.
Việc này được thực hiện bằng cách xác định các nhóm / phiên bản / tài nguyên API mà server hiện tại không nhận biết, rồi chuyển tiếp yêu cầu tới một peer có thể xử lý được.
- Nếu API server peer gặp lỗi khi phản hồi, API server nguồn sẽ trả về lỗi 503 ("Service Unavailable").
Cách hoạt động bên trong
Khi một API server nhận yêu cầu tài nguyên, nó kiểm tra xem API server nào có thể xử lý yêu cầu đó. Việc kiểm tra này dựa trên API StorageVersion nội bộ.
-
Nếu tài nguyên đã được API server nhận biết (ví dụ:
GET /api/v1/pods/some-pod), yêu cầu sẽ được xử lý tại chỗ. -
Nếu không có đối tượng
StorageVersionnào tương ứng với tài nguyên yêu cầu (ví dụ:GET /my-api/v1/my-resource) nhưngAPIServicetương ứng được cấu hình để proxy đến một API server mở rộng, thì yêu cầu sẽ được xử lý theo luồng proxy mở rộng. -
Nếu có một đối tượng
StorageVersionhợp lệ cho tài nguyên được yêu cầu (ví dụ:GET /batch/v1/jobs) và API server đang cố xử lý yêu cầu đó (gọi là handling API server) đã tắt nhóm APIbatch, thì handling API server sẽ truy xuất danh sách các API server ngang hàng (peer API servers) có phục vụ nhóm API / phiên bản / tài nguyên tương ứng (trong trường hợp này làapi/batch/v1) dựa trên thông tin từ đối tượngStorageVersionđã truy xuất. Sau đó, handling API server sẽ chuyển tiếp (proxy) yêu cầu đến một trong những kube-apiserver ngang hàng phù hợp, vốn có khả năng xử lý tài nguyên được yêu cầu.-
Nếu không có peer nào khả dụng cho nhóm / phiên bản / tài nguyên đó, API server sẽ trả lại lỗi 404 ("Not Found").
-
Nếu có peer phù hợp nhưng không phản hồi (do lỗi mạng, hoặc thông tin về peer chưa được đăng ký đúng lúc), thì API server sẽ trả về lỗi 503 ("Service Unavailable").
-
3 - Containers
Containers Kubernetes
3.1 - Các biến môi trường của Container
Trang này mô tả các tài nguyên có sẵn cho các Containers trong môi trường Container.
Môi trường container
Môi trường Container trong Kubernetes cung cấp một số tài nguyên quan trọng cho Container:
- Một hệ thống tệp tin (filesystem), là sự kết hợp của một image và một hoặc nhiều volumes.
- Thông tin về chính container đó.
- Thông tin về các đối tượng (object) khác trong cluster.
Thông tin container
Hostname của một Container là tên của Pod mà Container đang chạy trong đó.
Có thể lấy thông tin qua lệnh hostname hoặc lệnh gọi hàm
gethostname
trong libc.
Tên của Pod và namespace có thể lấy ở các biến môi trường thông qua downward API.
Các biến môi trường do người dùng định nghĩa từ định nghĩa của Pod cũng có trong thông tin của Container, như là mọi biến môi trường khác được xác định tĩnh trong Docker image.
Thông tin cluster
Một danh sách tất cả các services đang chạy khi một Container được tạo đều có trong Container dưới dạng các biến môi trường. Các biến môi trường này đều khớp với cú pháp của các Docker links.
Đối với một service có tên là foo ánh xạ với Container có tên là bar, các biến sau được xác định:
FOO_SERVICE_HOST=<host mà service đang chạy>
FOO_SERVICE_PORT=<port mà service đang chạy>
Các services có địa chỉ IP và có sẵn cho Container thông qua DNS nếu DNS addon được enable.
Tiếp theo là gì
- Tìm hiểu thêm về Container lifecycle hooks.
- Trải nhiệm thực tế attaching handlers to Container lifecycle events.
3.2 - Container Lifecycle Hooks
Trang này mô tả cách mà kubelet quản lý các Container có thể sử dụng framework Container lifecycle hook để chạy mã nguồn được kích hoạt bởi các sự kiện trong lifecycle của nó.
Tổng quan
Tương tự như nhiều framework ngôn ngữ lập trình có thành phần các lifecycle hooks, như là Angular, Kubernetes cung cấp các Container cùng với các lifecycle hook. Các hooks cho phép các Container nhận thức được các sự kiện trong lifecycle của chúng và chạy mã nguồn được triển khai trong một trình xử lý khi lifecycle hook tương ứng được thực thi.
Container hooks
Có 2 hooks được cung cấp cho các Containers:
PostStart
Hook này thực thi ngay sau khi một container được tạo mới. Tuy nhiên, không có gì đảm bảo rằng hook này sẽ thực thi trước container ENTRYPOINT. Không có tham số nào được truyền cho trình xử lý (handler).
PreStop
Hook này được gọi tức thì ngay trước khi một container bị chấm dứt bởi một API request hoặc sự kiện quản lý như liveness/startup probe failure, preemption, tranh chấp tài nguyên và các vấn đề khác. Một lời gọi tới PreStop hook thất bại nếu container ở trạng thái đã chấm dứt (terminated) hoặc đã hoàn thành (completed) và hook phải hoàn thành trước khi tín hiệu TERM được gửi tới để dừng container.
Thời gian gia hạn chấm dứt của Pod bắt đầu trước khi hook PreStop được chạy, nên Container cuối cùng sẽ chấm dứt trong thời gian gia hạn chấm dứt của Pod bất kể kết quả của handler là gì.
Không có tham số nào được truyền cho trình xử lý (handler).
Xem thêm chi tiết về hành vi chấm dứt (termination behavior) tại Termination of Pods.
Các cách thực hiện Hook handler (Hook handler implementations)
Các Containers có thể truy cập một hook bằng cách thực hiện và đăng ký một handler cho hook đó. Có 3 loại hook handler có thể được triển khai cho các Containers:
- Exec - Thực thi một lệnh cụ thể, như là
pre-stop.shtrong cgroups và namespaces của Container. Tài nguyên được sử dụng bởi lệnh được tính vào Container. - HTTP - Thực thi một HTTP request với một endpoint cụ thể trên Container.
- Sleep - Dừng container trong một khoảng thời gian. Đây là tính năng đang ở
beta-level, được tự động bật bởi
PodLifecycleSleepActionfeature gate.
Lưu ý:
Tính năng betaPodLifecycleSleepActionAllowZero được bật mặc định từ bản v1.33.
Tính năng này cho phép bạn thiết lập thời gian sleep là 0 giây (hay không thực hiện hành động
nào) cho các hooks Sleep lifecycle của bạn.Thực thi hook handler (Hook handler execution)
Khi một hook quản lý Container lifecycle được gọi,
hệ thống quản lý Kubernetes thực thi trình xử lý (handler) dựa trên hành động của hook.
httpGet, tcpSocket (deprecated) và sleep được thực thi bởi tiến trình kubelet, còn exec được thực thi trong container.
Lời gọi hook PostStart handler được khởi tạo khi một container được tạo,
nghĩa là container ENTRYPOINT và hook PostStart được kích hoạt đồng thời.
Tuy nhiên, nếu hook PostStart mất quá nhiều thời gian để chạy hoặc bị treo,
container không thể chuyển sang trạng thái running.
Các hooks PreStop không được thực thi bất đồng bộ với tín hiệu dừng Container; hook phải được hoàn thành thực thi trước khi tín hiệu TERM được gửi.
Nếu hook PreStop bị treo khi thực thi, Pod phase ở trạng thái Terminating và tiếp tục cho tới khi bị chấm dứt sau terminationGracePeriodSeconds hết hạn. Khoảng thời gian gia hạn này bằng tổng thời gian mà cả hook PreStop thực thi và Container dừng lại một cách bình thường.
Ví dụ, nếu terminationGracePeriodSeconds là 60, và hook mất 55 giây để hoàn thành, và Container mất thêm 10 giây để dừng lại sau khi nhận được tín hiệu, thì Container sẽ bị chấm dứt trước khi nó kịp dừng bình thường, vì terminationGracePeriodSeconds nhỏ hơn tổng thời gian cần thiết để thực hiện hai việc này (55+10).
Nếu hook PostStart hoặc PreStop thất bại,
nó sẽ xóa Container.
Người dùng nên làm cho hook handlers nhẹ nhất có thể. Tuy nhiên, có những trường hợp khi những lệnh chạy dài có ý nghĩa, chẳng hạn như khi lưu trạng thái trước khi dừng một container.
Hook delivery guarantees
Hook delivery được trù định ít nhất một lần,
điều đó có nghĩa là hook có thể được gọi nhiều lần cho bất kỳ sự kiện cho trước nào,
chẳng hạn như PostStart hoặc PreStop.
Tùy thuộc vào việc thực hiện hook để xử lý việc này một cách chính xác.
Nhìn chung, chỉ có các deliveries đơn được thực hiện. Ví dụ, nếu một HTTP hook receiver bị down và không thể nhận các traffic, sẽ không được gửi lại. Tuy nhiên, trong một số trường hợp hiếm hoi, delivery kép có thể xảy ra. Chẳng hạn, nếu một kubelet khởi động lại ở giữa quá trình gửi một hook, hook có thể được gửi lại sau khi kubelet quay trở lại.
Debugging Hook handlers
Log cho một Hook handler không được hiển thị trong các Pod events.
Nếu một handler thất bại vì lí do nào đó, nó sẽ broadcast một event.
Đối với PostStart, đây là event FailedPostStartHook,
và đối với PreStop, đây là event FailedPreStopHook.
Để tự tạo ra một event lỗi FailedPostStartHook, bạn có thể điều chỉnh file
lifecycle-events.yaml
để thay đổi lệnh postStart thành "badcommand" và áp dụng nó.
Dưới đây là một số ví dụ output của events từ việc chạy lệnh kubectl describe pod lifecycle-demo:
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 7s default-scheduler Successfully assigned default/lifecycle-demo to ip-XXX-XXX-XX-XX.us-east-2...
Normal Pulled 6s kubelet Successfully pulled image "nginx" in 229.604315ms
Normal Pulling 4s (x2 over 6s) kubelet Pulling image "nginx"
Normal Created 4s (x2 over 5s) kubelet Created container lifecycle-demo-container
Normal Started 4s (x2 over 5s) kubelet Started container lifecycle-demo-container
Warning FailedPostStartHook 4s (x2 over 5s) kubelet Exec lifecycle hook ([badcommand]) for Container "lifecycle-demo-container" in Pod "lifecycle-demo_default(30229739-9651-4e5a-9a32-a8f1688862db)" failed - error: command 'badcommand' exited with 126: , message: "OCI runtime exec failed: exec failed: container_linux.go:380: starting container process caused: exec: \"badcommand\": executable file not found in $PATH: unknown\r\n"
Normal Killing 4s (x2 over 5s) kubelet FailedPostStartHook
Normal Pulled 4s kubelet Successfully pulled image "nginx" in 215.66395ms
Warning BackOff 2s (x2 over 3s) kubelet Back-off restarting failed container
Tiếp theo là gì
- Xem thêm về Container environment.
- Kinh nghiệm thực hành gắn các trình xử lý vào các sự kiện trong lifecycle của Container.